크롤링
💡
웹 페이지를 그대로 가져와서 데이터를 추출해 내는 행위
인터넷에 존재하는 많은 정보를 사람이 하나씩 찾기는 매우 어렵다.
따라서 이를 필요한 것만 탐색하기 위하 크롤러를 사용한다.
크롤링과 스크래핑
크롤링
탐색에만 초점을 맞춘다.
해당 페이지에 방문 후 그 페이지의 내용과 링크의 복사본을 저장한다.
스크래핑
정보 추출에 초점을 맞춘다.
예
특정 게시판의 게시글들의 조회수를 추출한다.
특정 게시글의 작성자 이름을 추출한다.
특정 페이지 입력창의 input element을 추출한다.
정적 크롤링과 동적 크롤링
페이지 형태가 동적인 형태로 많이 바뀌게 되면서 크롤링도 동적 크롤링을 많이 사용하는 추세이다.
| 정적 크롤링 | 동적 크롤링 |
|---|---|
| 한 페이지 내 원하는 정보가 전부 드러나는 정적인 데이터를 크롤링하여 가져오는 것 | 여러 페이지를 이동하며 마우스로 클릭하거나 타이핑을 통한 입력으로 확인할 수 있는 데이터를 가져오는 것 |
| 빠름 | 느림 |
관련 모듈
Python
- beautifulsoup
- selenium
Java
- soup
사용해보기
windows11, chrome 환경에서 진행한다.
Selenium with Python - Selenium Python Bindings 2 documentation
Note This is not an official documentation. If you would like to contribute to this documentation, you can fork this project in GitHub and send pull requests. You can also send your feedback to my email: baiju.m.mail AT gmail DOT com. So far 50+ community members have contributed to this project (See the closed pull requests).
설치하기
다음 명령어를 입력하여 selenium을 설치한다.
pip install selenium시작하기
아래 코드를 입력하여 python.org 사이트를 크롤링해보자
코드
from selenium import webdriver
# Chrome WebDriver 인스턴스 생성
driver = webdriver.Chrome()
# 해당 페이지로 이동
# -> 해당 페이지가 완전히 로드되면 다음으로 넘어감
driver.get("http://www.python.org")
# 제목에 Python이라는 것이 있는지 확인
assert "Python" in driver.title
print(driver.title)
driver.close()출력
Welcome to Python.org
종료 코드 0(으)로 완료된 프로세스실제 사이트의 title과 일치하는지 확인하기 위해 직접 사이트에 접속한다.
개발자 도구(F12)를 눌러 요소에서 “title”을 검색한다.
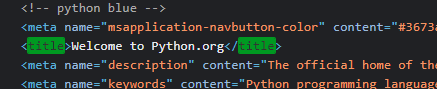
실제 추출한 값과 일치함을 확인한다.
입력 처리
실제 input element에 데이터를 입력한 결과를 추출해보자
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
# Chrome WebDriver 인스턴스 생성
driver = webdriver.Chrome()
# 해당 페이지로 이동
# -> 해당 페이지가 완전히 로드되면 다음으로 넘어감
driver.get("http://www.python.org")
# q라는 name을 가진 element를 추출한다.
elem = driver.find_element(By.NAME, "q")
# 해당 element에 입력값이 존재할 경우 전부 지운다.
elem.clear()
# 해당 element value에 pycon이라는 값을 넣는다.
elem.send_keys("pycon")
# 해당 값을 제출한다.
elem.send_keys(Keys.RETURN)
# 값이 존재하지 않으면 오류를 낸다.
assert "No results found." not in driver.page_source
# 브라우저 창을 종료한다.
driver.close()동작방식
element중 q라는 이름을 가진 element를 찾는다.
elem = driver.find_element(By.NAME, "q")
search-field 즉, 검색창인 것을 알 수 있다.
해당 위치에 값이 존재하면 전부 지운다.
elem.clear()
해당 element에 pycon이라는 값을 넣는다.
elem.send_keys("pycon")
해당 값을 제출한다.
elem.send_keys(Keys.RETURN)XPath
코딩교육 티씨피스쿨
4차산업혁명, 코딩교육, 소프트웨어교육, 코딩기초, SW코딩, 기초코딩부터 자바 파이썬 등
💡
문서의 구조를 통해 경로 위에 지정한 구문을 사용하여 항목을 배치하고 처리하는 방법
위치 경로
| 경로 연산자 | 설명 |
|---|---|
| 노드 이름 | 해당 ‘노드 이름’과 일치하는 모든 노드를 선택 |
| / | 루트 노드부터 순서대로 탐색 |
| // | 현재 노드의 위치와 상관 없이 지정된 노드에서부터 탐색 |
| . | 현재 노드를 선택 |
| .. | 현재 노드의 부모 노드를 선택 |
| @ | 속성 노드를 선택 |
필터 표현식
특정 노드를 선택하기 위한 방법 대괄호([])를 이용
| 표현식 | 설명 |
|---|---|
| p_languages/language[1] | <p_languages>요소의 자식 노드 중 첫 번째 <language>요소를 선택함. |
| p_languages/language[position() < 3] | <p_languages>요소의 자식 노드 중 처음 두 개의 <language>요소를 선택함. |
| p_languages/language[last()] | <p_languages>요소의 자식 노드 중 마지막 <language>요소를 선택함. |
| //priority[@rating] | rating 속성을 가지고 있는 <priority>요소를 모두 선택함. |
| //priority[@rating = 3] | rating 속성의 속성값이 3인 <priority>요소를 모두 선택함. |
| count(//language) | 모든 <language>요소의 개수를 반환함. |
포함식
XPath and XQuery Functions and Operators 3.1
python.org 에서 Download라는 텍스트가 들어있는 element를 찾아보자
실제 개발자도구에서 검색 시 해당 element를 추출해야한다.
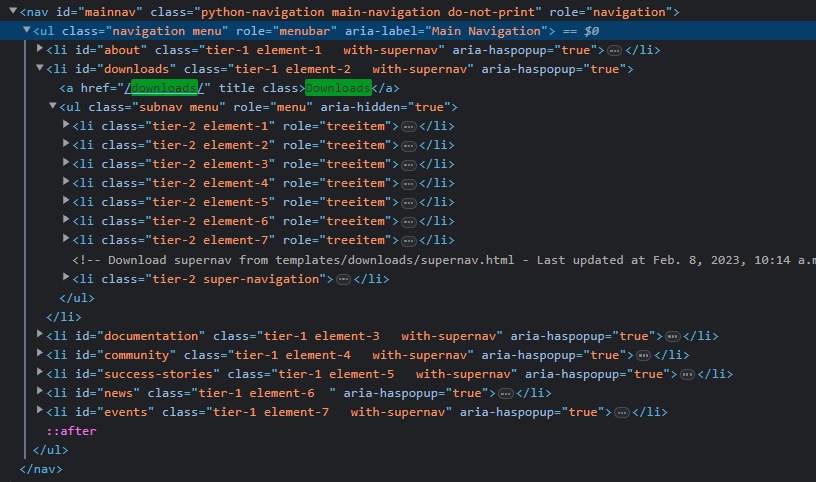
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
# Chrome WebDriver 인스턴스 생성
driver = webdriver.Chrome()
# 해당 페이지로 이동
# -> 해당 페이지가 완전히 로드되면 다음으로 넘어감
driver.get("http://www.python.org")
# Download라는 값을 가진 element의 부모->부모 원소를 찾는다.
elem = driver.find_element(By.XPATH, "//*[contains(text(),'Download')]/../..")
print(elem.text)
# 브라우저 창을 종료한다.
driver.close()결과
About
Downloads
Documentation
Community
Success Stories
News
EventsUploaded by N2T
'최신기술' 카테고리의 다른 글
| N2T 프로그램 사용 오류 시 (0) | 2023.02.07 |
|---|---|
| ChatGPT (0) | 2023.02.07 |