
제한적 직접 실행 원리
OS는 시간 공유를 통해 물리적 CPU를 공유한다.
이를 이용하여 여러 작업들이 동시에 실행되는 것처럼 보이도록한다.
이를 구현하기 위해서 성능 저하, 제어 문제 를 해결해야 한다.
제한적 직접 실행
프로그램을 빠르게 실행하기 위하여 제한적 직접 실행 기법을 사용한다.
이는 단순히, 프로그램을 CPU 상에서 그냥 직접 실행시키는 것이다.
- 문제점
- 사용자가 잘못된 일을 한다면 판단하기가 쉽지 않음
- OS가 CPU의 제어 권한을 얻는 것이 쉽지 않음
개요
스캐줄링- 현재 프로세스를 중단하고 다른 프로세스를 실행하기로 결정 → 운영체제는 문맥교환(Context Switch)코드를 실행
워크로드- 프로세스가 동작하는 일련의 행위
아래 스케줄링 방법은 다음을 가정한다.
- 작업은 동일한 시간 동안 실행
- 모든 작업이 동시에 도착
- 모든 작업은 CPU만 사용 (I/O 작업은 하지 않는다)
- 런타임이 알려짐
스케줄링의 평가 항목
반환 시간= 완료 시간 - 도착 시간공정성- A, B, C …
1. 선입선출 FIFO, FCFS
단순히 먼저 온 작업을 먼저 처리하는 것
예시
- A, B, C 작업이 동시에 도착했다면..(각 작업은 10의 시간을 소모한다)

$$
평균 반환시간= {(10+20+30)\over3}=20
$$
- A, B, C 작업이 동시에 도착했다면..(각 작업은 100, 10, 10 시간을 소모한다)

$$
평균 반환 시간 = {(100+110+120)\over3}=110
$$
장점
- 구현하기가 쉬움
단점
convoy effect- CPU 사용시간이 더 짧은 프로세스가 CPU를 오랜동안 사용하는 작업에 의해 미뤄지는 현상
2. 최단 작업 우선 SJF
단순히 최단 작업을 우선적으로 처리한다.
예시
- A, B, C 작업이 동시에 도착했다면..(각 작업은 100, 10, 10 시간을 소모한다)

$$
평균 반환 시간 = {(10+20+120)\over3}=50
$$
- A, B, C 작업이 A는 t=0, B와 C는 t=10에 도착했다면..(각 작업은 100, 10, 10 시간을 소모한다)

$$
평균 반환 시간 = {(100+(110-10)+(120-10))\over3}=103.33
$$
장점
- 동시에 도착했을 때
convoy effect가 발생하지 않는다.
단점
- 동시에 도착하지 않는다면 FIFO와 유사하게(convoy effect) 동작한다.
3. 최소 잔여 시간 우선 SRT, STCF
새로운 작업이 들어오면 잔여 시간을 비교하여, 잔여 시간이 가장 적은 작업 스케줄링
예시
- A, B, C 작업이 A는 t=0, B와 C는 t=10에 도착했다면..(각 작업은 100, 10, 10 시간을 소모한다)

$$
평균 반환 시간 = {((120-0)+(20-10)+(30-10))\over3}=50
$$
**응답시간을 알고 있을 때 최소 잔여 시간 우선 STCF 가 최적의 알고리즘이 된다.**
새로운 평가 기준 : 응답 시간
작업이 도착하는 시점부터 처음으로 스케줄 될 때 까지의 시간
$$
T_{response} = T_{firstrun}-T_{arrival}
$$
4. 라운드 로빈 RR
일정시간 실행 후 실행 큐 다음 작업으로 진행
**타임 슬라이스(time slice)**- 작업이 실행되는 일정 시간
예시
- A, B, C 작업이 동시에 도착한다. (A, B, C 각각 5초 동안 실행된다.)
- 타임 슬라이스는 5초로 한다.
$$
T_{average response}={0+5+10\over3}=5sec
$$
- A, B, C 작업이 동시에 도착한다. (A, B, C 각각 5초 동안 실행된다.)
- 타임 슬라이스는 1초로 한다.
$$
T_{average response}={0+1+2\over3}=1sec
$$
| 짧은 타임 슬라이스 | 긴 타임 슬라이스 | |
|---|---|---|
| 장점 | 응답시간이 매우 좋음 | 문맥 교환 비용을 줄일 수 있음 |
| 단점 | 문맥 교환이 빈번하게 발생하여 전체 성능에 영향을 미침 | 응답시간이 좋지 않음 |
가정의 완화
입출력 연산을 고려한다.
- I/O 완료를 기다리는 동안 프로세스는 대기 상태가 된다.
- I/O 가 완료되면 OS는 프로세스를 대기에서 준비 상태로 이동한다.


각 작업의 실행 시간을 미리 알지 못한다.
기존 스케줄링 정책들에 대한 평가
SJF, STCF : 반환 시간은 좋으나 응답 시간이 나쁨
RR : 응답 시간은 좋으나 반환 시간이 나쁨
5. 멀티 레벨 피드백 큐 MLFQ
미래를 예측하기 위해 기존 스케줄링 경험을 활용하는 스케줄링
반환 시간의 최적화 → 짧은 작업 먼저 실행
- 여러 고유 큐로 구성 Q1, Q2, Q3
- 실행할 준비가 된 작업은 하나의 큐 상에 존재
- 더 높은 우선 순위를 가진 작업이 실행되도록 선택
- 동일한 큐 내 작업은 RR 스케줄링 적용
규칙
- 더 높은 우선 순위를 가진 작업이 실행되도록 선택
- 동일한 큐 내 작업은 RR 스케줄링 적용
- 작업이 시스템에 진입 되면 가장 높은 우선 순위 부여
- 작업이 실행되는 동안 주어진
타임 슬라이스를 모두 사용하면, 우선 순위를 낮춤 - 작업이 주어진 타임 슬라이스를 소진하기 전에 CPU를 양도하면 우선 순위 유지
예시

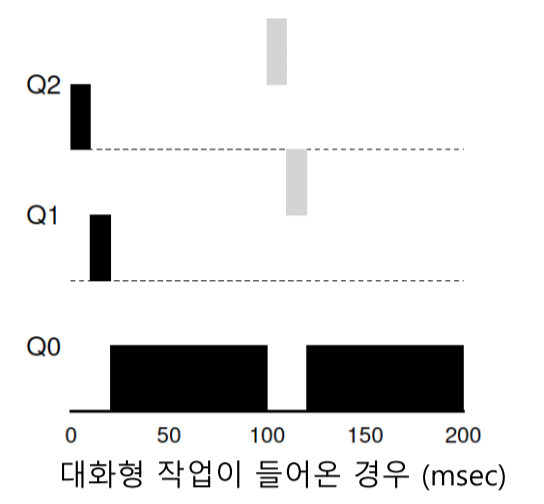
단점
- 단기간 실행되는 프로세스가 많으면, 긴 실행 작업은 CPU 시간을 할당 받지 못한다.
- 타임 슬라이스의 99%만 실행하고 I/O 작업을 실행하면, 높은 우선순위를 유지할 수 있다.
개선
- 일정 기간이 지나면 모든 작업을 최상위 우선 큐로 이동한다.
4. 주어진 단계에서 시간 할당량을 소진하면 우선 순위를 낮춘다.
- 낮은 우선 순위에 긴 할당 시간을 제공한다.
6. 비례 배분
- 각 작업에 일정 비율의 CPU 시간을 보장
- 반환 시간이나 응답 시간이 최적화되지는 않음
티켓- 프로세스가 받아야 하는 자원 공유 몫
- 예시
- 프로세스 A가 75장의 티켓을 가지면 → CPU의 75%를 사용
- 프로세스 B가 25장의 티켓을 가지면 → CPU의 25%를 사용
- 당첨된 티켓의 프로세스에 CPU를 할당
- 프로세스 A는 75% 확률로 CPU를 할당받는다.
보폭 스케줄링
보폭- 자신이 가진 티켓 수에 반비례하는 값
프로세스가 실행 되면 보폭 수 만큼 카운터를 증가시키고, 카운터가 가장 작은 프로세스 선택

완전 공정 스케줄링 CFS
모든 프로세스에게 CPU를 공정하게 배정하는 것이 목표
고정되지 않은 타임 슬라이스를 가진다
nice 값을 사용하여 우선순위를 제어한다.
효율적인 검색, 삽입, 삭제를 위해 레드-블랙 트리를 사용한다.
min_granularty- 최소 타임 슬라이스
nice- 프로세스의 우선 순위를 제어하는 변수
- -20~19의 정수 값
time_slice- $$
time_slice_k={weight_k\over \Sigma{_{n=0}^{n-1}}weight_i}*sched_latency
$$ vruntime- $$
vruntime_i=vruntime_i+{weight_0\over weight_i}*runtime_i
$$
레드-블랙 트리
균형 이진 트리
탐색 연산 시간 O(log n)
'Programming > [Operation System]' 카테고리의 다른 글
| 멀티 프로세서 스케줄링 (0) | 2022.11.03 |
|---|